
[CS fundamentals] Programs, Processes, and Threads
os, cs, interview, process, thread ·이 포스트는 What’s the Diff: Programs, Processes, and Threads에서 발췌 번역이라기보단 재창조한 포스트입니다. 오역이나 빠트린 부분이 있을 수 있으니 상세한 내용은 원 포스트를 참조하시기 바랍니다.
Programs
Program 이란, 1과 0으로 이루어진 하나의 binary file 덩어리를 이야기한다. (큰 분류에서 그렇다는 이야기이다. 1/0 으로 이루어진 binary file 이라고 해서 무조건 program 이라 할 수는 없으며, 해당 architecture 나 OS 에서의 executable binary file 이 만족해야 하는 조건을 갖추어야 한다.) 일반적으로 disk storage, ROM 등의 non-volatile비휘발성 매체에 저장되며, C/C++, Lisp, Pascal 등의 다양한 high-level programming language 를 이용하여 제작된다. 제작된 source code 파일은 compiler, linker 등을 거쳐 최종적으로 computer 에서 실행 가능한 instruction 들로 이루어진 executable binary file 을 형태로 저장되는데, 이러한 compile 과정을 거치지 않고 source code 를 바로 ‘interprete’ 하여 실행 가능한 Python, PHP, JavaScript, Ruby 등의 언어도 존재한다. 하지만 interpreting 언어이든, compile 언어이든 결국 최종적으로 CPU 에서 실행될 때에는 binary 형태로 memory 에 로드되는 과정을 거치게 된다.
How Processes Work
‘Program’ 이 실행되기 위해서는 binary code 뿐만이 아니라 다른 여러 가지 자원이 필요하다. 하나의 ‘program’ 이, 실행되기 위해서 필요로 하는 다른 resource 들과 함께 main memory 에 load 되어 실행될 때에 우리는 그것을 ‘Process’ 라 부른다. ‘Operating System’운영체제는 program 이 필요로 하는 추가적인 resource 들을 관리하고 할당해 주는 역할을 한다.
Program 이 실행되기 위해 필요로 하는 resource 들에는, register, program counter, stack 등이 있다. register 는 CPU의 한 부분으로, data holding place 역할을 하며, instruction 이나, storage address 등 process 실행에 필요한 다양한 data 를 저장한다. 현재 program sequence 의 어느 부분을 실행 중인지를 저장하거나 (program counter or instruction pointer), process memory 의 stack 의 주소를 저장하거나, 혹은 heap 의 주소를 저장하는 register 들이 각각 존재한다.
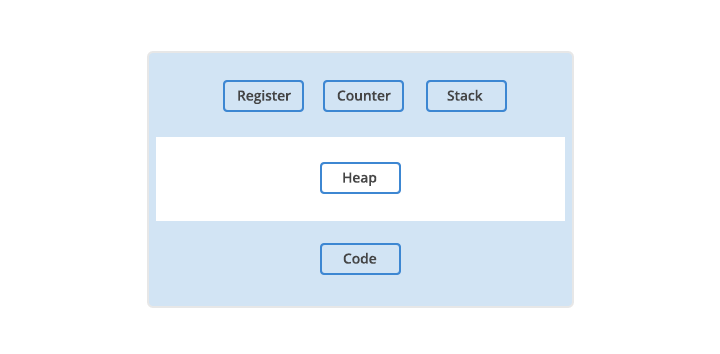
하나의 program 으로부터 여러 개의 instance 를 실행할 수 있으며 (Word processor 창을 여러 개 실행하듯), 각각의 instance 하나하나는 모두 별개의 ‘process’ 이다. 모든 process 는 다른 process 로부터 완전히 분리된 자기만의 memory address space 를 가지며, 이는 다른 process 로부터 완전히 독립적으로 실행됨을 의미한다. Process 는 다른 process 의 memory space 에 접근하지 못하며, memory space 의 전환은 OS 의 context switching 이라는 과정 - register와 memory 의 상태를 저장하고, 다른 process 의 register, memory 상태를 main memory 에 load - 을 통하여 이루어진다. OS 는 process 의 독립성을 보장함으로써, 특정 process 의 problem 이 다른 process 들 및 system 전반에 영향을 미치지 않도록 관리한다.
Process 의 memory 구조에 대해서는 이전 포스팅을 참고.
How Threads Works
‘Thread’ 는 process 내부에서의 ‘하나의 실행 단위’ (unit of execution) 이라고 할 수 있다. 하나의 process 는 단일 thread 로 이루어질 수도 있고, 여러 개의 thread (multi-threaded) 로 이루어질 수도 있다.
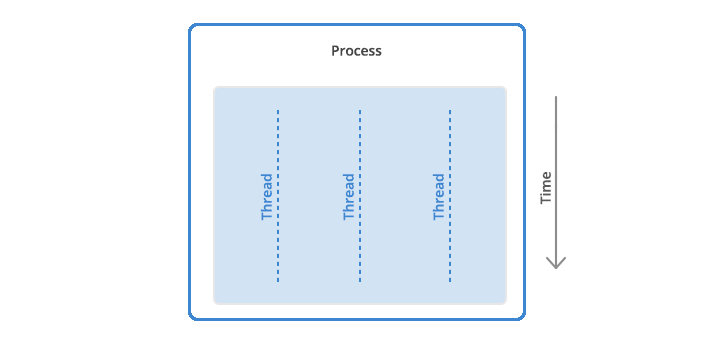
Process 내에서 모든 thread 는 memory address space 와 resource 를 공유하며, 여러 개의 thread는 동시에 실행될 수 있다. (역주: ‘동시’ 라는 의미에는 concurrency 와 parallelism 의 차이가 있긴 하지만, 이 주제는 여기에서 다루기는 조금 깊은 주제이므로 ‘거의 동시에’ 혹은 ‘논리적으로 동시에’ 정도로 이해하면 될 듯 하다. 원문에서는 이 동시성과 병렬성에 대해 맛보기 정도로 언급한 문단이 존재하므로 원한다면 원문을 읽어 보는 것이 이해에 도움이 될 것이다.)
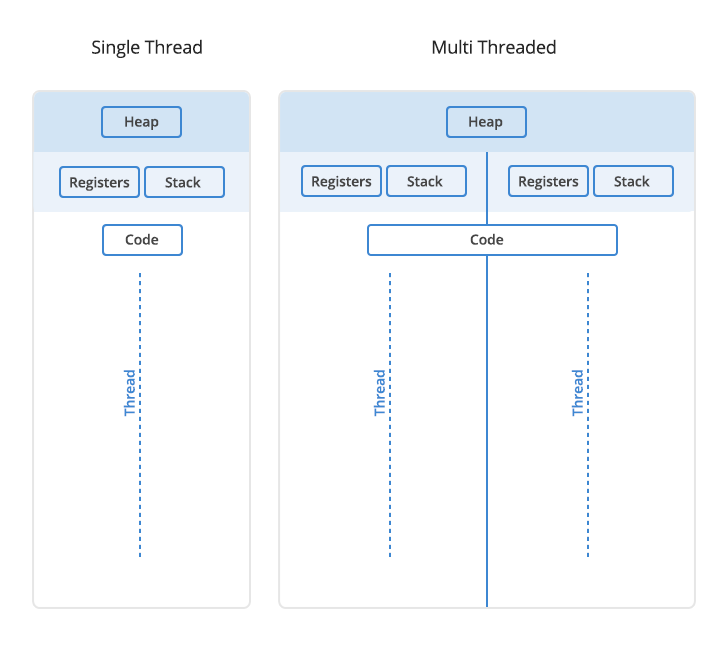
위에서, 모든 thread 는 memory address space 를 공유한다고 했는데, 동일한 memory address space 내에서 register 와 stack 은 thread 마다 별도로 존재하며, code, data, heap 영역은 서로 공유한다. stack 영역은 함수 호출시 전달되는 parameter set, return address와 함수 내에서 선언되는 local variable 등이 저장되는 영역으로, 이 stack 공간을 독립적으로 가진다는 것은 함수 호출 등의 독립적인 실행 흐름이 추가되는 것을 의미한다.
참고로, register set 의 공유는 system architecture 의 설계에 따라 조금씩 다르지만 일반적으로 process 전체의 register set 에 비해 thread 의 register set 의 크기가 더 작다. (sp - stack pointer, fp - frame pointer, pc - program counter 의 3개 register 를 독립적으로 가지는 경우가 일반적이다.) 따라서 process 간의 context switching 보다 thread 간의 context switching 비용이 적게 든다.
또한 CPU 의 cache memory 는 CPU 에서 한 번 읽어들인 data 를 caching 하고 있다가, 같은 data 에 접근시 이를 main memory 에서 읽어오는 대신 cache memory 에서 돌려주는데, 이 속도가 압도적으로 빨라 program 의 수행 시간에 절대적인 영향을 미친다. process 는 완전히 독립적인 memory address space 를 사용하므로, context switching 이 일어날 경우 이 cache 를 완전히 비우고 새로 caching 하게 되는 반면 thread 간의 전환에서는 (동일한 memory address space 를 사용하므로) cache memory reset 이 일어나지 않아 그만큼 cache hit 비율이 높아지고 program 수행의 속도가 빨라진다. 실제로 multi-process 와 multi-thread program 간의 수행 속도의 차이는 거의 이 cache hit 비율에서 오는 것이 대부분이다.
Thread 는 ligthweight process 라고도 불리며, 이처럼 program 수행에 많은 이점을 가져다 주는 존재이지만, 단점도 존재한다. (세상 모든 일에는 trade-off 가 있다.공짜는 없다) register 와 stack 을 제외한 memory 영역을 공유하기 때문에, 여러 개의 thread 를 생성할 경우 주의를 기울이지 않으면 synchronization동기화 문제가 발생한다. 예를 들면, 2개의 thread 가 동시에 global 변수 (data 영역에 저장된) 에 접근하여 그 값을 1 증가시키는 code 를 수행하는 경우를 보자. code 상으로는 var++ 의 1 line 이지만, 실제 CPU에서는 여러 개의 instruction 으로 수행된다. (register 에서 값을 불러 오고, 1 증가시키고, 다시 register 에 넣고… 등, 상세한 과정은 역시 너무 깊은 이야기이므로정확히 기억하고 있지 못하므로 생략) 이 여러 개의 instruction 을 수행하는 도중에 thread 간의 context switching 이 일어날 경우, 최종적으로는 변수 값이 1만 증가한다던지 (2개의 thread 가 해당 code 실행을 마쳤는데도) 하는 문제가 발생할 수 있다. 따라서 이런 경우를 방지하기 위해 multi-thread program 을 작성할 때에는 mutex, semaphore 등의 synchronization control 이 필수적으로 사용되어야 한다.
Threads vs. Processes
Wrap-up:
- Program 은 programming code 를 담고 있는 일종의 텍스트 파일에서 출발한다.
- Program 은 compile 혹은 interprete 과정을 통해 최종적으로는 binary form 으로 변환되어 실행된다.
- Program 이 실행되기 위해서는 main memory 상에 load 되어야 한다.
- Program 은 1개 혹은 여러 개의 process 로 이루어진다.
- Process 는 다른 process 로부터 완전히 독립적으로 실행된다.
- Thread 는 일종의 subset of process 라고도 할 수 있다.
- Thread 간의 communication 은 process 간의 그것보다 훨씬 쉽다. (memory address space 를 공유하므로)
- Thread 는 다른 thread 의 수행에 영향을 끼칠 수 있어 (공유 메모리의 접근) 주의가 필요하다.
Processes vs. Threads - Advantages and Disadvantages
| PROCESS | THREAD |
|---|---|
| (비교적) 무겁다 | (비교적) 가볍다 |
| 독립적인 memory address space 를 가진다 | 자신이 속한 process 의 memory address space 를 공유한다 |
| Process 간의 communication 이 어렵고 느리다 | (memory 를 공유하므로) threads 간의 communication 이 가볍고 빠르다 |
| Context switching 비용이 비싸다 | Context switching 비용이 싸다 |
| 다른 process 와 memory space 를 공유하지 않는다 | (같은 process 내의) 다른 thread 들과 memory space 를 공유한다 |